智能知识——深度学习入门必须理解这25个概念(2) 点击:51 | 回复:1






楼主最近还看过

9、成本函数(Cost Function)——当我们建立一个网络时,网络试图将输出预测得尽可能靠近实际值。我们使用成本/损失函数来衡量网络的准确性。而成本或损失函数会在发生错误时尝试惩罚网络。
我们在运行网络时的目标是提高我们的预测精度并减少误差,从而最大限度地降低成本。最优化的输出是那些成本或损失函数值最小的输出。
如果我将成本函数定义为均方误差,则可以写为:
C= 1/m ∑(y–a)^2,
其中 m 是训练输入的数量,a 是预测值,y 是该特定示例的实际值。
学习过程围绕最小化成本来进行。
10、梯度下降(Gradient Descent)——梯度下降是一种最小化成本的优化算法。要直观地想一想,在爬山的时候,你应该会采取小步骤,一步一步走下来,而不是一下子跳下来。因此,我们所做的就是,如果我们从一个点 x 开始,我们向下移动一点,即Δh,并将我们的位置更新为 x-Δh,并且我们继续保持一致,直到达到底部。考虑最低成本点。
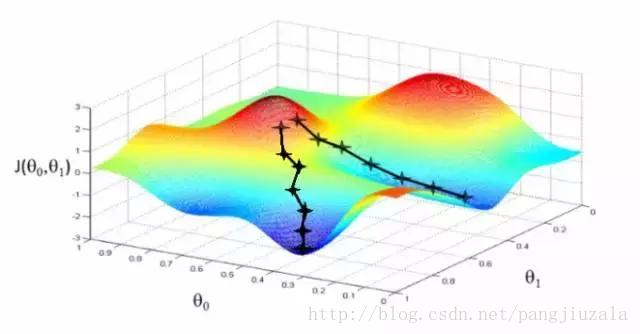
在数学上,为了找到函数的局部最小值,我们通常采取与函数梯度的负数成比例的步长。
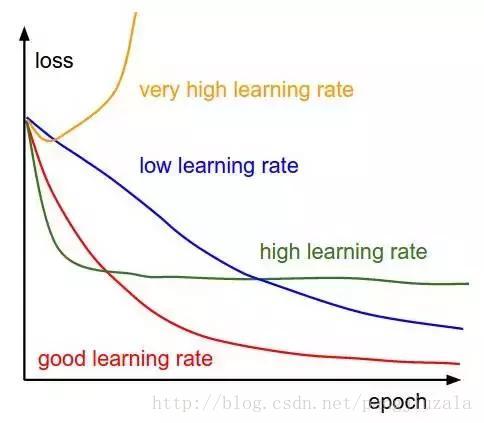
11、学习率(Learning Rate)——学习率被定义为每次迭代中成本函数中最小化的量。简单来说,我们下降到成本函数的最小值的速率是学习率。我们应该非常仔细地选择学习率,因为它不应该是非常大的,以至于最佳解决方案被错过,也不应该非常低,以至于网络需要融合。
12、反向传播(Backpropagation)——当我们定义神经网络时,我们为我们的节点分配随机权重和偏差值。一旦我们收到单次迭代的输出,我们就可以计算出网络的错误。然后将该错误与成本函数的梯度一起反馈给网络以更新网络的权重。 最后更新这些权重,以便减少后续迭代中的错误。使用成本函数的梯度的权重的更新被称为反向传播。
在反向传播中,网络的运动是向后的,错误随着梯度从外层通过隐藏层流回,权重被更新。
13、批次(Batches)——在训练神经网络的同时,不用一次发送整个输入,我们将输入分成几个随机大小相等的块。与整个数据集一次性馈送到网络时建立的模型相比,批量训练数据使得模型更加广义化。
14、周期(Epochs)——周期被定义为向前和向后传播中所有批次的单次训练迭代。这意味着 1 个周期是整个输入数据的单次向前和向后传递。
你可以选择你用来训练网络的周期数量,更多的周期将显示出更高的网络准确性,然而,网络融合也需要更长的时间。另外,你必须注意,如果周期数太高,网络可能会过度拟合。
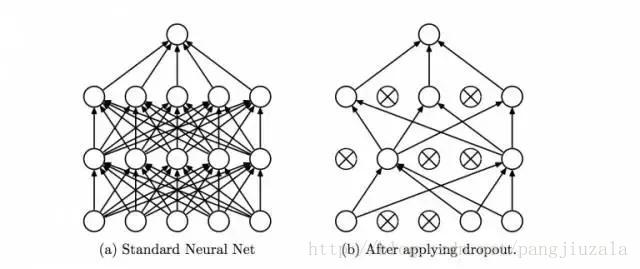
15、丢弃(Dropout)——Dropout 是一种正则化技术,可防止网络过度拟合套。顾名思义,在训练期间,隐藏层中的一定数量的神经元被随机地丢弃。这意味着训练发生在神经网络的不同组合的神经网络的几个架构上。你可以将 Dropout 视为一种综合技术,然后将多个网络的输出用于产生最终输出。
16、批量归一化(Batch Normalization)——作为一个概念,批量归一化可以被认为是我们在河流中设定为特定检查点的水坝。这样做是为了确保数据的分发与希望获得的下一层相同。当我们训练神经网络时,权重在梯度下降的每个步骤之后都会改变,这会改变数据的形状如何发送到下一层。
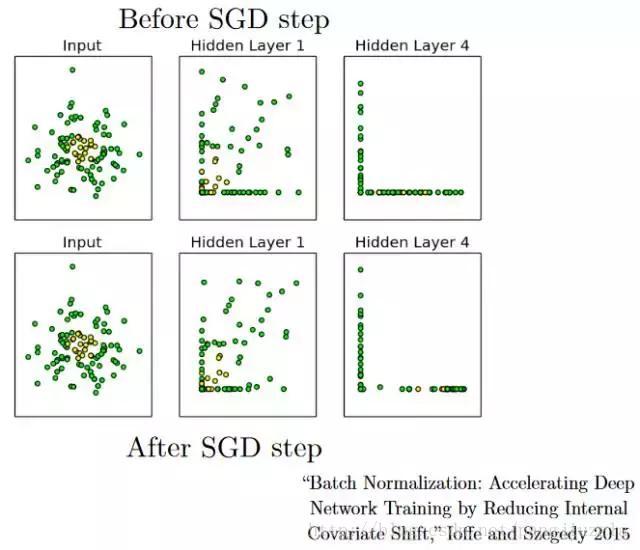
但是下一层预期分布类似于之前所看到的分布。 所以我们在将数据发送到下一层之前明确规范化数据。
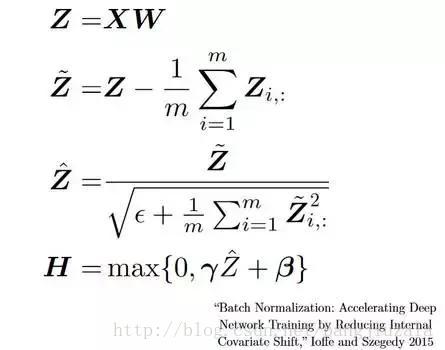
卷积神经网络
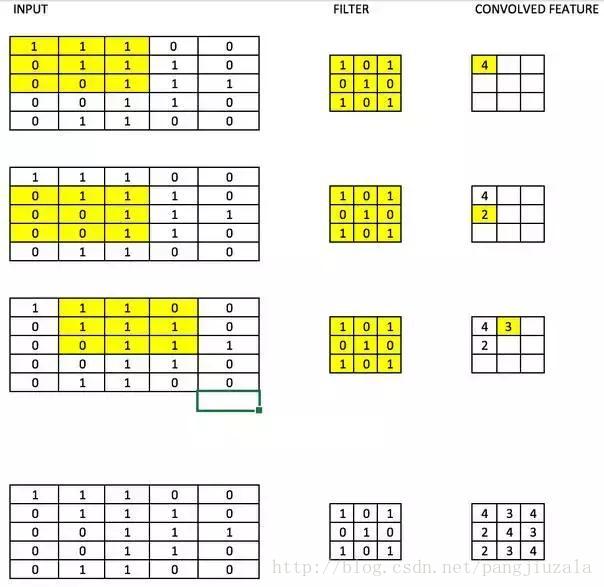
17、滤波器(Filters)——CNN 中的滤波器与加权矩阵一样,它与输入图像的一部分相乘以产生一个回旋输出。我们假设有一个大小为 28 28 的图像,我们随机分配一个大小为 3 3 的滤波器,然后与图像不同的 3 * 3 部分相乘,形成所谓的卷积输出。滤波器尺寸通常小于原始图像尺寸。在成本最小化的反向传播期间,滤波器值被更新为重量值。
参考一下下图,这里 filter 是一个 3 * 3 矩阵:
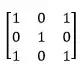
与图像的每个 3 * 3 部分相乘以形成卷积特征。
- 方原柏:拖料式定量皮带秤的皮...
 [1646]
[1646] - APS中复杂动态分组批的剖析[908]
- 新文明的曙光:读涂子沛先生新...[841]
- 许永硕:边缘计算是个啥?[788]
- 世界上历史最长的企业是哪家...[661]
- 方原柏:WirelessHART无线网关...[1552]
- 深度探究:智能工厂常见的三种...[747]
- MES制造执行系统在工业4.0中...[756]
- 小牛自动化:数码大方实体设计...[671]
- 西门子1200PLC存在的2个bug[3217]

官方公众号

智造工程师
-

 客服
客服

-

 小程序
小程序

-

 公众号
公众号











 工控网智造工程师好文精选
工控网智造工程师好文精选
