BY供应链计划引擎三种算法的再讨论 点击:1 | 回复:0

发表于:2025-11-13 02:09:40
楼主
如何制定一个生产和分销总计划,才能让整个公司的总利润最高(或总成本最低)?
而这个问题,是通过全局优化的线性规划。总利润最高(或总成本最低)是优化目标,而方法是通过线性规划的方式。
但是总利润最高(或总成本最低)的优化涉及财务信息。我不清楚现在Blue Yongder是如何制定优化目标,在早期版本中,是根据订单优先级来优化。
比如:在手订单小于产能时,有订单就接收,通常情况下订单都是盈利的,这无须算法优化。只有到了订单量和产能接近,或者订单量大于产能时,线性规划是根据订单优先级来优化,订单优先级高的优先计划。
而订单优先级的设定,就是比较关键的。如果订单优先级没有根据利润率、客户重要性做区分,订单的优先级是按照交货时间由近到远、订单批量由小到大的顺序排列。即交货期越近的优先级越高,订单批量越小的的优先级越高。
当然实施项目时,可以根据需求,自行设定优先级。
在学习FP资料时特别好奇,为什么按这个交货时间,订单批量设定优先级。所以特别关注优先级设定这一块,后来看了排程算法才知道,按照这个规则交付订单数量最大,延迟交付订单最少。
所以制定一个生产和分销总计划,让整个公司的总利润最高(或总成本最低)是目标,而通过设定订单优先级,将财务目标和计划目标解耦。
二、MAP采用启发算法(逐单计划)
在i2 FP刚刚诞生时,计算资源还是非常稀缺的。
在i2工作时,同事讲过一个故事:华为刚开始做集成供应链项目时,每月一次计划的时间要接近20小时(第一天晚上运行计划、要到第二天中午才能完成计划,需要在第二天工作时间前做完计划)。为此华为不惜重金,要求i2派最优秀的专家优化,保证计划时间的及时性。
因此早期计划,对所有产品、所有区域完全计划是非常消耗资源的,通常是一个周期(月、周)做计划,当有调整时,针对单个产品、单个物料做计划。
每次计划根据预测需求量制定计划需求量,如下图,七月份的产品A的需求预测量是180,但经过团队确认的未来计划需求量是160,未来生产的产能计划是按160的量来计划的。
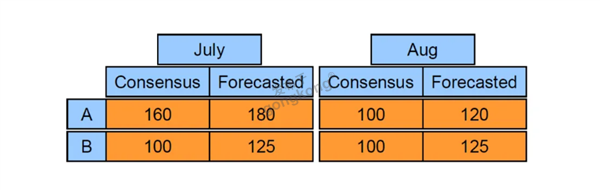
计划完成后,这160的计划量中,已经有一些订单,这些是分配订单,剩余的生产量,留给ATP,这个ATP就是可以接受的新订单量。
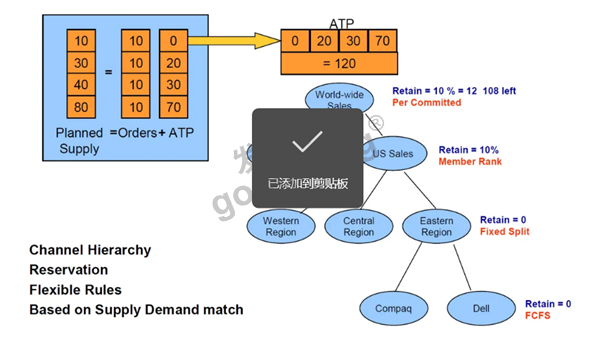
如果ATP大于零,可以接受订单,一旦ATP=0时,再有新订单进来,就需要是否考虑接受新订单,这时的新选择无非:加班、增加设备、产能外包,或者甩掉不重要订单。无论哪种选择,都需要更改设置,针对这个订单影响的产品、设备、原料重新计划。
这个就是启发式算法。
三、Deep Tree采用递归分层算法。
在付兵的文章中,第三部分介绍的分层算法(ICP -> CAO -> AS),这里我不再赘述。
只想说的是如果对于所有资源都采用递归分层算法,资源消耗是很大的。
因此CAO通过计划保证大颗粒度(长周期,地点汇总、产品系列)的产能与生产的相对平衡后,排产是需要小颗粒度(时间维度天、小时、分钟;地点维度车间、设备;产品维度具体产品)的生产能够执行。
分层的优点在于保证大颗粒度的相对平衡后,小颗粒度排产是在计划的框架内执行,通常不会在排产阶段去修改计划,从而保证计算资源的合理的使用。
而排产的优化空间在于生产批次的汇总。一种生产包括准备时间、生产时间、冷却时间;合理排产,将相同品类的生产集中生产,可以提高效率。
比如汽车喷漆,从红色转化成蓝色需要有较长的冷却、准备时间。将红色汽车、蓝色汽车的生产汇总。





楼主最近还看过
热门招聘
相关主题

官方公众号

智造工程师
-

 客服
客服

-

 小程序
小程序

-

 公众号
公众号











 工控网智造工程师好文精选
工控网智造工程师好文精选
