TDMS 大文件读写内存溢出?教你三招彻底解决 点击:81 | 回复:0

在 LabVIEW 数据采集中,TDMS 是最常用的数据存储格式。然而系统长时间连续采集时,TDMS 文件体积不断增大,极易触发内存溢出错误。本文深入分析 TDMS 大文件读写的内存瓶颈,详解分块读取、数据抽稀、预分配缓冲区三种解决策略,并通过案例说明如何在不丢数据的前提下实现长时间连续采集与实时波形显示。
一、背景:TDMS 与内存问题的根源
TDMS(Technical Data Management Streaming)是 NI 的二进制数据存储格式,具有写入快、效率高、支持多元数据类型等优点,广泛应用于振动监测、噪声测试等长时间采集系统中。
典型场景:写 VI 将传感器数据持续写入 TDMS 文件,读 VI 从同一文件读取数据用于实时波形显示。运行几小时后,内存占用攀升,最终弹出“内存不足”错误。
根源在于两个误区:
1. 一次性读取全部数据:每次读取整个 TDMS 文件到内存,文件达数百 MB 时内存瞬间耗尽。
2. 无限制拼接数组:读取的数据不断追加到显示数组中,旧数据从不释放。
二、三大核心解决策略
策略一:分块读取(Chunked Reading)
使用场合:从大体积 TDMS 文件读取数据,文件大小超过可用内存 10% 以上时。
原理:不将整个文件一次性加载到内存,按固定点数分批读取。例如每次只读 10,000 个点,处理完再读下一批。
实现要点:
使用 TDMS Read VI 的 offset 参数指定起始位置
每次读取后 offset = offset + numberOfSamplesRead
持续循环直到读取全部数据
注意事项:
分块后不能直接用索引访问全部数据,需维护位置映射表。
块大小需平衡内存占用和 I/O 次数。块越小内存越低,但 I/O 次数增加。
策略二:数据抽稀(Data Decimation)
使用场合:需要在波形图表(Waveform Graph/Chart)上实时显示长时间采集数据时。
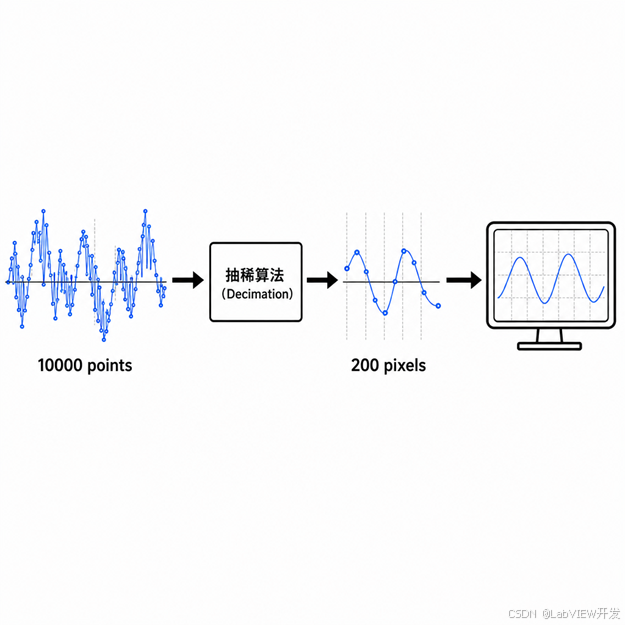
原理:显示器的像素宽度是有限的,例如波形图表控件宽度仅为 200 像素。如果试图在 200 像素上绘制 10,000 个数据点,意味着每个像素要堆叠 50 个点,这不仅是显示资源的浪费,也会因为 GDI 对象的激增导致内存泄漏。
数据抽稀的核心思想是:显示的精度不需要超过显示设备的物理分辨率。因此,在将数据送往显示控件之前,先进行降采样处理。
实现要点:
计算抽稀比例:decimationFactor = totalPoints / displayWidth
常用的抽稀算法:最大值-最小值抽稀(保留每个区间内的最大最小值,能较好地保留信号包络)
对抽稀后的数据进行显示
注意事项:
抽稀仅用于显示,不要影响原始数据的存储完整性。写入 TDMS 文件的仍然应该是全量原始数据。
如果需要在抽稀后进行频域分析,应使用原始数据而非抽稀后的数据。
抽稀比例不宜过大,否则会丢失信号的细节特征。一般建议保持在 2~10 倍之间。
![]()
图1:数据抽稀原理示意图
策略三:预分配缓冲区 + 环形覆盖(Pre-allocated Buffer & Circular Overwrite)
使用场合:长时间连续运行的数据采集系统,要求程序无限制运行而不重启,且仅保留最近一段时间的数据。
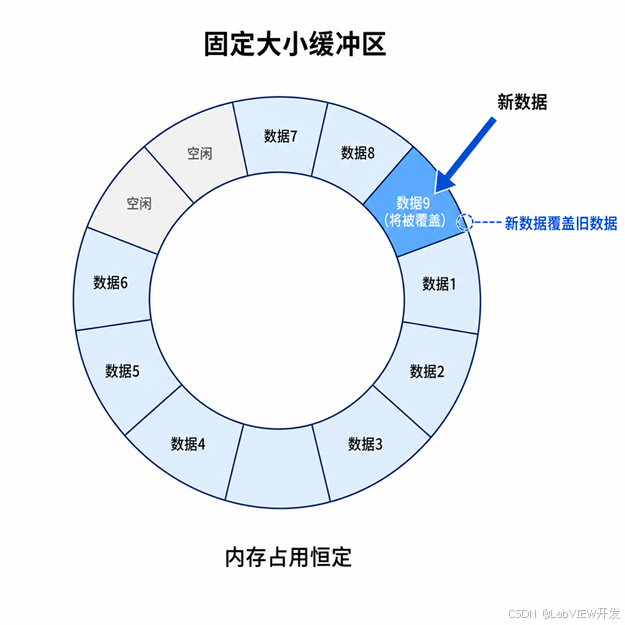
原理:在程序启动时预先分配一个固定大小的数组,将其全部填充为占位数据。采集过程中,新数据不断覆盖数组中的旧数据,内存占用始终保持恒定,不会随时间增长。
实现要点:
预先计算所需的最大缓冲区大小:bufferSize = sampleRate × 保留时长
使用 "Replace Array Subset" 而不是 "Build Array" 来更新数据
配合取模运算实现环形索引
注意事项:
预分配的大小需在程序启动前确定,运行中无法动态扩展。
如果需要保存全部历史数据,该策略不适用,应改用策略一(分块读取)配合多文件轮转。
与"分文件存储"策略的关系:当数据量超过单个 TDMS 文件的设计上限时(例如希望将文件大小限制在 1GB 以内),可以配合多文件轮转策略:监测当前文件大小,达到阈值后关闭旧文件并创建新文件继续写入。但需注意,TDMS 文件不支持从文件中间删除数据。如果确实需要固定大小的环形文件,只能通过"读取全部数据到内存 → 删除旧数据 → 全部写回"的方式实现,这在文件体积较大时效率很低。
![]()
图2:预分配缓冲区 + 环形覆盖示意图
三、三种策略的对比
|
对比维度 |
分块读取 |
数据抽稀 |
预分配缓冲区 |
|
核心用途 |
降低单次读取的内存峰值 |
降低显示资源消耗 |
消除内存动态增长 |
|
内存占用 |
随块大小可控 |
影响显示部分,不涉及存储 |
恒定不变 |
|
实现复杂度 |
★★☆ 中等 |
★☆☆ 简单 |
★★★ 较高 |
|
适用阶段 |
数据读取 |
数据显示 |
数据写入/存储 |
|
是否丢失信息 |
否,但需管理 offset |
是,显示精度降低 |
是,旧数据被覆盖 |
|
实时性影响 |
块越小 I/O 越多 |
几乎无影响 |
无额外 I/O |
|
推荐组合 |
配合预分配使用 |
配合其他两种策略 |
配合分块读取使用 |
四、实际应用案例
案例背景
某噪声监测项目需要对工业现场的噪声信号进行 7×24 小时不间断采集。采样率 51.2 kS/s,每通道连续采集,共 2 个通道。系统需要实时显示最近 10 分钟的波形,同时将全部数据保存到 TDMS 文件以供后续分析。
问题
初始版本采用最简单的编程方式:每次读取整个 TDMS 文件,并将数据全部追加到显示数组中。系统运行约 2 小时后,内存占用超过 2GB,波形图表响应严重滞后,最终程序崩溃。
解决方案
采用“分块读取 + 数据抽稀 + 预分配缓冲区”三管齐下的方案:
第一步:预分配显示缓冲区
采样率 51.2 kS/s × 2 通道 × 600 秒(10 分钟)= 61,440,000 个数据点
程序启动时预先分配一个 61,440,000 元素的二维数组,填充为 NaN 或 0
采集到的数据通过 "Replace Array Subset" 替换数组中的对应位置
第二步:分块读取历史数据
设置分块大小为 100,000 点/次
使用 TDMS Read VI 并传入正确的 offset 参数
每次处理完当前块后更新 offset
配合进度条显示读取进度
第三步:抽稀显示
波形图表宽度为 800 像素,计算抽稀比例:decimationFactor = dataPoints / 800
采用最大值-最小值保留算法,确保波形的峰值特征不被丢失
将抽稀后的数据送波形图表显示
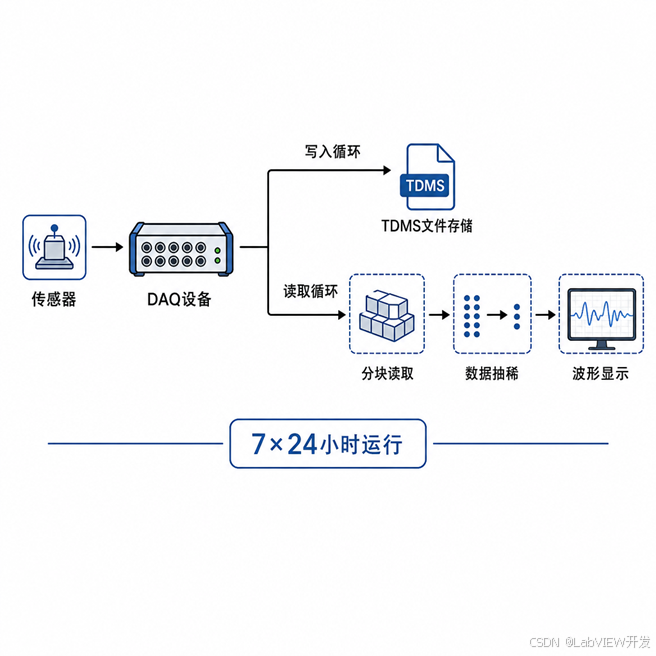
图3:噪声监测项目系统架构图
实施效果
|
指标 |
优化前 |
优化后 |
|
连续运行时间 |
约 2 小时 |
> 72 小时(按需终止) |
|
峰值内存占用 |
> 2 GB |
约 150 MB |
|
波形图表刷新率 |
约 1 fps |
> 30 fps |
|
数据完整性 |
崩溃时丢失 |
100% 保存在 TDMS 中 |
五、使用注意事项总结
分块大小的选择:块大小 = 采样率 × 刷新周期 × 通道数。例如 1 秒刷新一次,块大小 = 52k × 1 × 2 ≈ 100k 点,既保证实时性,又不会占用过多内存。
文件锁定冲突:同一个 TDMS 文件同时被写 VI 和读 VI 访问时,需要使用 TDMS 的并发访问机制(参考 NI 自带的 "Concurrent Access to TDMS File" 示例)。写入和读取应在不同的循环中,且读操作始终读取已经落盘的数据。
多文件轮转的考量:如果需要长时间保存全部数据而不仅仅是最近一段,应使用"定时轮转"策略——每小时或每天创建一个新的 TDMS 文件,而不是试图在一个文件中无限写入。文件命名建议包含时间戳。按时间轮转还有一个好处:当某一天的数据文件损坏时,不会影响其他时段的数据。
DVR 的适用场景:当需要在读写 VI 之间共享数据而不依赖 TDMS 文件时,可以考虑使用 DVR(Data Value Reference)。DVR 允许在内存中创建引用,多个 VI 通过引用访问同一块内存区域,避免了数据的复制开销。但需注意,DVR 管理的是内存中的数据,断电后会丢失,不适合需要持久化存储的场景。
不要过度抽稀:如果后续需要对数据做 FFT 分析或其特征提取,在显示层面的抽稀不应该影响原始数据的保存。建议将原始数据无压缩地写入 TDMS,抽稀仅用于 UI 显示路径。
六、总结
TDMS 文件读写中的内存溢出问题,本质上是 LabVIEW 开发者对"数据生命周期"管理不足造成的。解决的核心思路只有一条:控制任何时候驻留在内存中的数据量。
写入路径:使用预分配缓冲区 + 多文件轮转,消除内存增长
读取路径:使用分块读取 + offset 偏移管理,降低内存峰值
显示路径:使用数据抽稀,减少显示资源消耗
这三种方法可以独立使用,但组合使用时效果最佳。对于长时间运行的采集系统,建议在设计阶段就将上述策略纳入架构设计,而不是等到出现内存溢出后再“打补丁”。






官方公众号

智造工程师
-

 客服
客服

-

 小程序
小程序

-

 公众号
公众号











 工控网智造工程师好文精选
工控网智造工程师好文精选
