工业数据分析与建模:重点是做什么? 点击:170 | 回复:0

我从90年开始,就开始做数据分析和建模工作,做出来了一点成绩、也积累了一些经验,甚至提出了一些理论。但却总感觉这些想法不系统、知识结构很乱。最近为了准备一次课,我把思路整理了一下,突然有点豁然开朗的味道。
数据分析和建模到底是做什么的?其实是分析、发现和应对干扰的。干扰有两种:一种是随机的干扰、一种是系统性的干扰。我们在教科书上学习的统计方法,几乎都是应对随机干扰的,而不是非随机的系统干扰。如果有了显著的系统性干扰,传统的统计学方法就无效了。这个问题怎么办呢?我认为:大数据时代,重点就是发现和应对非随机干扰。
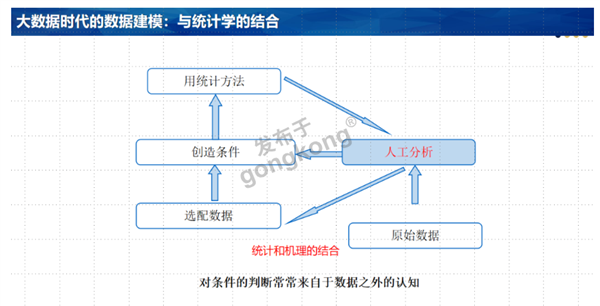
我十年前就意识到:在工业大数据时代,数据一般不适合传统的统计方法;数据建模最重要的工作是创造条件,通过选配和构造数据,让数据符合统计学的需求。这样,就可以用统计学知识解决数据分析和建模的问题了。那么,“创造条件”又是咋回事呢?前天突然意识到:所谓创造条件,关键就是发现、确认和去除系统干扰。
建模的时候,我们面对的直接问题是减少误差。我们可以把模型的误差分成三类:一类是模型的逼近误差,一类是(自变量或因变量)采集时产生的随机误差,一类则是系统性的干扰。对于模型的逼近误差,人们有很多办法,就不必多说了;对随机(不可见)误差,人们是没有任何办法的、必须承认它的存在。所以,数据分析和建模的工作重点其实就是发现和处理系统干扰带来的误差。
工厂关心的系统性干扰,其实就是“非随机”干扰。在工业现场,一种常见的现象是缺陷率有时突然变得很高、过段时间又会突然降低。这时,人们一般估计是某个事件发生了,但却不知道是什么事情导致的。这样的事件,就是我们关心的系统性干扰。
我们做数据分析和建模的重点,就是要找到、确认这些系统性干扰。想到这里,我突然有一种豁然开朗的感觉:因为我过去经常总结出来的一些思想、方法和手段,其实都是为了发现和确认系统干扰。这些,许多知识就在我的脑子里串起来了。课程的体系就逻辑就完整起来了。一般来说,一旦系统干扰被确定之后,建模方法往往就简单多了。
特别需要指出的是:系统性干扰可能有两种表现。假设企业关心产品性能的指标,则系统性干扰可能导致两种变化:一种影响指标的均值、一种影响指标的标准差。后面这种情况经常被忽视,但现实中却非常有用。
科技发展有一种规律:往往从技术尺度逐渐走向工程尺度。AI是这样,数据分析技术似乎也是这样。
来源:微信号 蝈蝈创新随笔
作者:郭朝晖
该作品已获作者授权,未经许可,禁止任何个人及第三方转载。





楼主最近还看过

官方公众号

智造工程师
-

 客服
客服

-

 小程序
小程序

-

 公众号
公众号











 工控网智造工程师好文精选
工控网智造工程师好文精选
