激光雷达点云技术:普通人也能看懂的 3D 环境感知原理 点击:13 | 回复:0

当自动驾驶汽车在车流中平稳行驶、仓储机器人在货架间精准避障、无人机对山林完成三维测绘时,背后都离不开一项核心感知技术 —— 激光雷达点云。它就像机器的 “立体眼睛”,能把真实世界的三维形态完整复刻进数字空间。
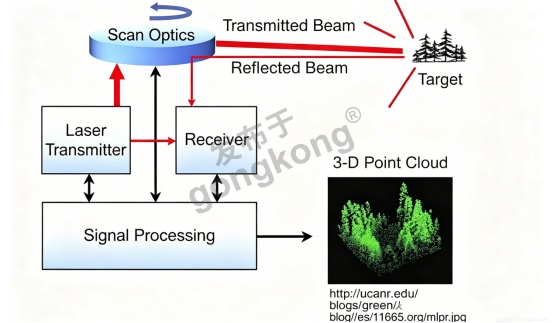
激光雷达的工作原理本质上是 “用光来测距”。设备向外发射高频激光脉冲,光线遇到物体表面后反射回来,系统通过精确计算光的飞行时间(ToF),就能算出雷达与目标点之间的距离。这和蝙蝠用回声定位的逻辑异曲同工,只不过把声波换成了速度更快、指向性更强的激光。
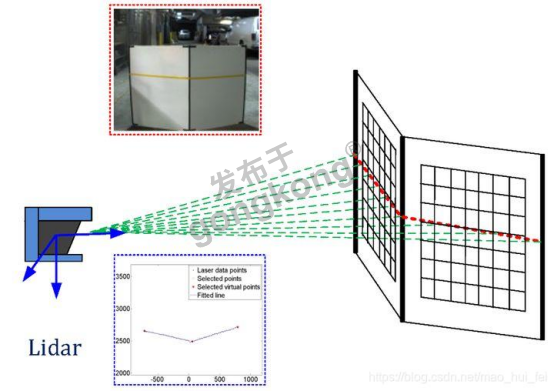
单次测距只能得到一个点的距离信息,而激光雷达通过内部的旋转扫描结构或固态扫描器件(如微振镜、面阵闪光),让激光束快速扫过周围空间,每秒可发射数十万到数百万个激光点。每个点都携带着精确的三维空间坐标(X、Y、Z),还附带激光反射强度信息。海量三维点聚合在一起,就构成了我们常说的 “点云”。
如果把普通摄像头拍摄的 2D 照片比作平面画布上的像素画,点云就是把真实世界拆解成无数个悬浮在空间中的三维坐标点。它不仅能告诉你 “前方有物体”,还能精确说出 “物体有多远、多大、是什么形状”。点云中的每个点都真实对应着物理世界的一个表面位置,不存在透视变形,受光照明暗、逆光眩光的影响远小于摄像头,夜间也能正常工作。
原始点云只是一堆离散的坐标数据,要实现环境感知还需要算法层层处理。首先通过点云聚类,把属于同一个物体的点聚合在一起,区分出一个个独立的目标;接着进行语义识别,判断每个目标的类别 —— 是地面、行人、车辆还是建筑;再通过特征提取与帧间匹配,计算出目标的大小、朝向和运动速度。对于测绘、数字孪生等场景,还会通过点云配准把不同角度、不同时刻的数据拼接成完整的三维模型。最终机器就能 “看懂” 周围环境:哪里可通行、哪里有障碍物、障碍物正在往哪个方向移动。
相比纯视觉方案,激光雷达点云的核心优势在于高精度深度感知与环境鲁棒性。近距离测距精度可达厘米级,且不依赖环境光照,不易被平面图像的视觉错觉误导。正因如此,它成为自动驾驶、工业机器人、智慧测绘、古建筑数字化保护等领域不可或缺的感知手段。
随着固态激光雷达成本下降与点云算法迭代,这项曾经的高端测绘技术正在走入更多场景。小到扫地机器人的室内建图,大到智慧城市的数字孪生,激光雷达点云正在为机器构建越来越清晰的三维世界认知,也让智能设备的环境感知能力不断逼近人类的立体视觉。





楼主最近还看过

官方公众号

智造工程师
-

 客服
客服

-

 小程序
小程序

-

 公众号
公众号











 工控网智造工程师好文精选
工控网智造工程师好文精选
